I stumbled upon a website that had something uncanny about it. This was the Hero:
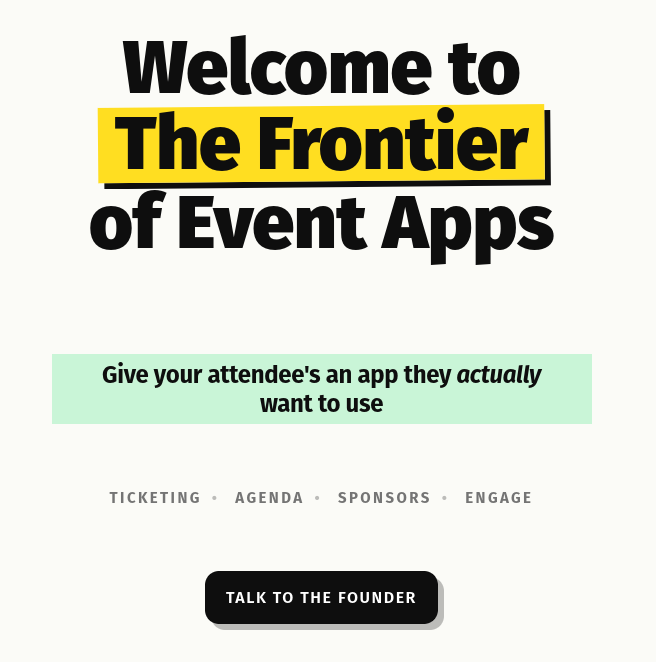
Their Hero.
After some more scrolling:
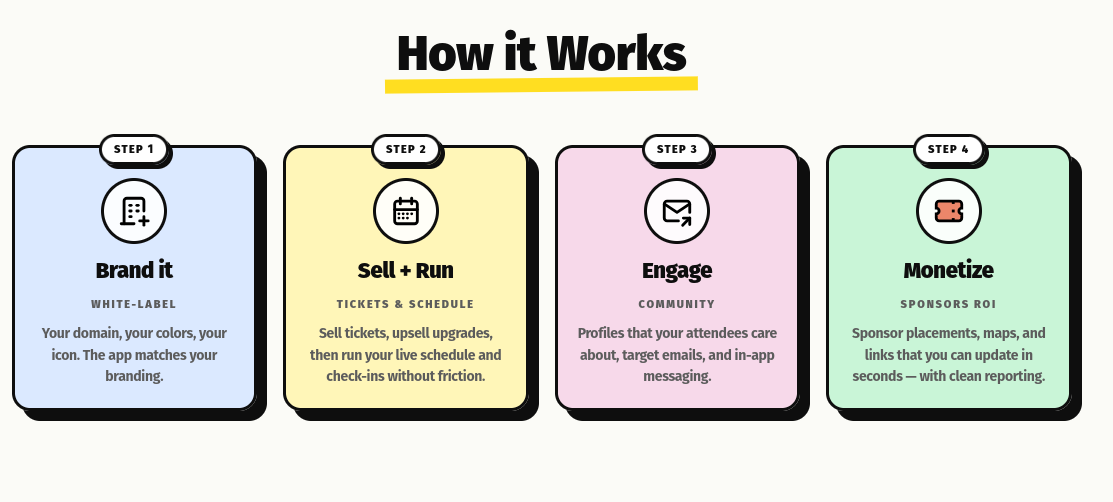
Their "How it Works" Section.
.
Wait.
This is getting really similar to Kavla (my sideproject) “How it Works” section.
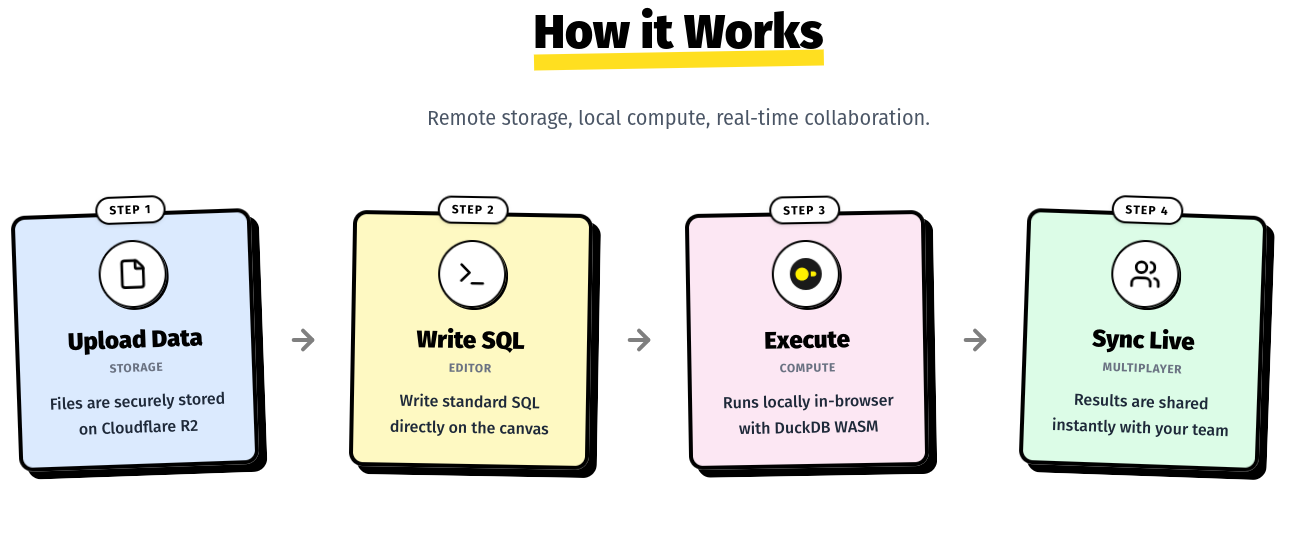
Kavla's section (now replaced)
I’m not the one to jump to conclusions though. This could just be a huge coincidence!
Then I checked their css:
/* Yellow underline highlight
like Kavla */
h3::after {
content: "";
position: absolute;
left: -4%;
right: -4%;
bottom: -3px;
height: 14px;
background: var(--yellow);
z-index: -1;
transform: rotate(-0.6deg);
}
Hmmm. 🤔
To comfort myself on this ridiculous inspect-elemented theft I made some bad memes.
sorry
That could have been the end of the story.
.
.
But I sent them a snarky email.
Alex (Me)
Hello! I'm building Kavla. I found your site and we have a very similar design! Coincidence!
Have you tried it out? What did you think?
Might as well ask for some product feedback right?
Instead, I got a quick and honest reply.
Them (Milan)
Heyy! Yes i may have used you guys as an inspiration base... sorry im not even sure what your product does I just loved the landing page design.
Imitation is flattery right ?? My landing page is still evolving.. but yes for now I definitely took inspiration.
Ok so Milan admitted to copying my design. Good for my ego!
But that he doesn’t understand what Kavla does is concerning. I sent him a follow up email asking for more and got this response:
Milan
Honestly to tell you the truth looking at Kavla again I still don't understand what service you are providing. And I've been on the site a fair few times as I was using the look & feel as a direct inspiration.
I'm a solo developer and recent founder. I've been working as a developer for quite some time. I honestly still have no idea from the landing page what the product is actually for.
You put a lot of care and attention to this I can see and I really like the UI!
Ouch.
So we have this person, who is a former dev, now founder, that after looking at my landing page for hours to copy it, still doesn't understand wtf Kavla is about.
That is… not good.
I’m aiming to wow people that work professionally with SQL (Data Engineers, Analysts, Data Scientists). They didn’t fit this persona. But they should still be able to figure out what it is I’m actually building.
We ended up exchanging a few more emails. I was gaining insight after insight, such a treasure trove!

My own personal treasure, available over email! Long John Silver would be super jealous
I came to realize I had been over indexing on selling collaboration. I am super excited about how awesome tldraw (the canvas I’m using) makes multiplayer. I really wanted to go all in on showcasing it.
However, this led me to neglect selling Kavla’s core utility. After all, multiplayer is something you only care about after you enjoy the product in single player.
I also tried to tighten it so it’s clearer what the value prop is:
Kavla is for messy, non-linear analytics where notes, screenshots and questions live just next to the SQL and charts.
The new landing page is available on kavla.dev. Check it out!
Shoot me an email, I’d love to know what you think ([email protected]). And try the product too!
Also have a look at Milan’s company Conference Cowboy. He’s building a white label event app. Awesome guy!